
티스토리 뷰
개요
최근 웹 애플리케이션 서버의 URL 패턴 매핑 기능을 직접 구현하던 중, 접두사 매칭(Prefix match)에 대한 요구사항을 마주하게 되었다. 예를들어 사용자에게 /user/test/123로 URL 요청이 오면 /user/test/* 와 /user/* 중 더 구체적인 패턴, 즉 가장 긴 접두사인 user/test/* 가 매핑되어야 했다.
정확히 일치하는 URL을 찾는 것이라면 HashMap 자료 구조를 이용하여 O(1)로 처리할 수 있다. 하지만 와일드 카드(*)가 포함된 접두사 매칭은 일반적인 해시 기반 탐색만으로 해결하기 어려웠다. 때문에 순차 탐색으로 startsWith()와 longest 변수를 두어 요청 URL과 접두사가 일치하고 가장 긴 패턴이면 갱신하도록 구현하였다. 시간 복잡도는 순차 탐색이므로 O(n) (패턴 수에 비례)이다.
[Mapper 코드 일부]
// 2. Prefix match (가장 긴 prefix 우선)
StandardWrapper prefixMatch = null;
int longest = -1;
for (Map.Entry<String, StandardWrapper> entry : prefixMappings.entrySet()) {
String prefix = entry.getKey();
if (uri.startsWith(prefix) && prefix.length() > longest) {
prefixMatch = entry.getValue();
longest = prefix.length();
}
}
시간 복잡도가 O(n)이므로 추가 개선 방법이 없을까 고민하였다. 첫 번째로 고려한 개선 방향은 이진 탐색(Binary Search)을 적용하여 O(logN)으로 탐색 효율을 높이는 것이였다.
정렬된 URL 패턴 목록이 있다면, 클라이언트 요청 URL에서 접두사를 잘라가며 이진 탐색을 반복해 가장 긴 매칭 패턴을 찾는 방식을 떠올렸다.
예를 들어 URL 패턴이 사전순으로 정렬되어있다고 가정하자.
/account/*
/account/login/*
/account/profile/*
/book/*
/book/detail/*
...그리고 요청 URL이 /account/login/page 라고 하면, 접두사 매칭을 위해 아래와 같이 접두사를 줄여가며 확인해야한다.
/account/login/page => 없음
/account/login => 있음
/account => 있음하지만 이 구조에는 접두사를 줄여가며 이진 탐색을 여러 번 수행해야 한다. URL 문자열(세그먼트 개수)이 L개 이면 탐색에 O(L logN)시간 복잡도가 발생한다.
Trie(Prefix Tree)
이진 탐색을 이용한 방식은 아이디어는 괜찮지만, 접두사를 잘라가며 여러번 이진 탐색을 반복해야 한다는 점에서 한계를 가진다. 이러한 문제를 해결하기 위한 대안으로 문자열을 구조적으로 탐색할 수 있는 자료구조인 Trie가 널리 사용된다.
Trie(트라이)는 "Retrieval Tree"의 줄임말로, 문자열의 접두사 기반으로 정보를 저장하고 검색할 수 있도록 설계된 트리 기반 자료구조이다.
등록된 URL패턴이 아래와 같이 있다고한다면 "/"기준으로 하나의 노드로 구성한다.
[등록 되어있는 URL 패턴들]
/user/*
/user/mypage/*
/user/login/*
/user/login/view*
/user/login/page/edit/*
/home/board/*
/home/news/*
/home/foot/*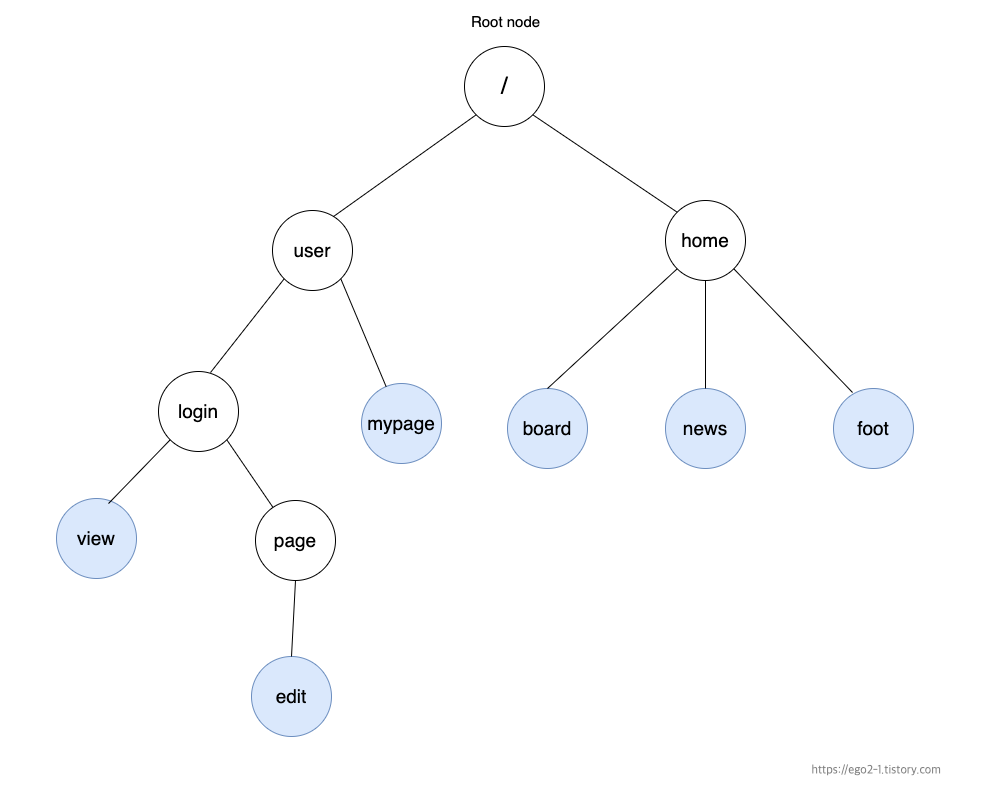
TrieNode
public class TrieNode {
// 현재 노드가 하나의 URL segment를 의미
Map<String, TrieNode> children = new HashMap<>();
boolean isPatternEnd = false; // 이 노드에서 패턴이 끝나는지 여부
Controller value = null; // URL패턴과 매핑된 정보(Servlet, Controller 등)
}
Trie 삽입
URL 패턴은 "/"기준으로 분리한 후, 각 segment를 순차적으로 TrieNode에 삽입한다.(segment: "/"구분되는 문자열)
이미 존재하는 segment는 그대로 재사용하며, 새로운 segment가 등장하면 노드를 생성한다. 패턴의 마지막 노드에는 `isPatternEnd = true`로 표시하고, 매핑된 서블릿 혹은 컨트롤러 객체(`Controller`)를 `value` 필드에 저장한다.
`isPatternEnd == true`일 경우에 여기까지 탐색한 경로가 하나의 완성된 URL 패턴이고, 이 요청에 대해 컨트롤러(또는 서블릿)를 반환할 수 있다는 것을 의미한다.
public class TrieRouter {
private final TrieNode root = new TrieNode();
public void insert(String pattern, Controller controller) {
String[] parts = pattern.split("/");
TrieNode node = root;
for (String part : parts) {
if (part.isEmpty()) continue;
node = node.children.computeIfAbsent(part, k -> new TrieNode());
}
node.isPatternEnd = true;
node.value = controller;
}
}삽입의 시간 복잡도는 L(= segment 개수)만큼 소요된다. URL이 `/user/login/page`이면 L=3, 즉 O(L)이다.
trieRouter.insert("/user/login/view", new LoginViewController()); // *생략
trieRouter.insert("/user/mypage", new MyPageController()); // *생략
Trie 탐색
요청 URL을 "/" 기준으로 분리한 후, 루트부터 자식 노드를 순차적으로 따라가면서 탐색한다. 탐색 중 isPatternEnd가 true인 노드를 만날 때마다 가장 최근 매칭된 노드를 갱신한다. 탐색이 끝나면 가장 긴 접두사에 대응하는 매핑 객체를 반환할 수 있다. 탐색도 마찬가지로 O(L)시간에 탐색 가능하다.
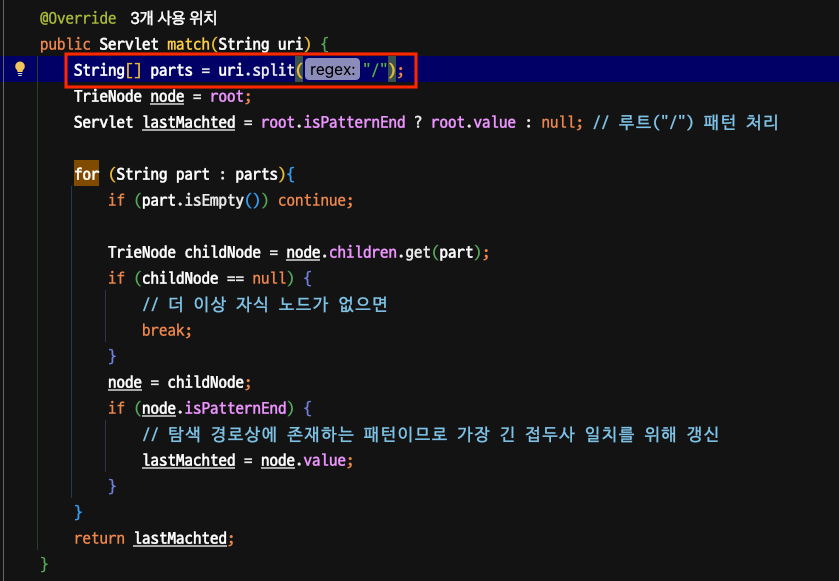
public Controller match(String uri) {
String[] parts = uri.split("/");
TrieNode node = root;
Controller lastMatched = null;
for (String part : parts) {
if (part.isEmpty()) continue;
if (!node.children.containsKey(part)) break;
node = node.children.get(part);
if (node.isPatternEnd) {
lastMatched = node.value;
}
}
return lastMatched;
}
[유저 URL 요청]
Controller ctrl = router.match("/user/login/view/detail");
// "/user/login/view/*" 와 매칭됨 → LoginViewController
성능 벤치마크
접두사 매칭 방식별로 순수 알고리즘 성능과 힙 메모리 사용량 비교를 위해, 다음 세가지 라우터 구현체에 대해 JMH(Java Microbenchmark Harness)를 이용하여 벤치마크를 수행하였다.
- LinearRouter: 패턴 리스트 순차 탐색하여 가장 긴 접두사 찾음 O(N)
- BinarySearchRotuer: 정렬된 접두사 리스트에 대해 이진 탐색 수행하며, 가장 긴 매칭 찾음 L X O(logN)
- TrieRouter: 요청 URI 세그먼트로 분리하여 Trie자료구조를 통해 탐색 O(L)
벤치마크 설정
- 사용자가 요청하는 URI 세그먼트 길이: 4~5개 (예: /user/login/view/detail)
- 라우터에 등록된 패턴 수: 1,000 / 10,000 / 100,000개 순으로 비교
- 초기 힙 크기, 최대 힙 크기: 2GB
- 측정 항목: Throughput(ops/s), 힙 메모리 사용량(B/op)
1차 벤치마크 - 처리량(Throughput)
처리량은 높을 수록 우수한 성능이다. ops/s는 초당 요청 처리 수를 말한다. Binary Search가 가장 우수하다.

BinarySearchRouter > TrieRouter > LinearRouter
1차 벤치마크 - 힙 메모리 사용량(B/op)
낮을수록 적은 메모리 사용량을 보여주는 것이다. 메모리 사용량이 적을 수록 우수하다.

LinearRouter < BinarySearchRouter < TrieRouter
일단 처음 결과를 받아봤을 때는 너무 당황스러웠다. Trie기반 라우터가 힙 메모리 사용량이 많은 것은 세그먼트마다 객체가 생성되므로 많을 것으로 예상 범위였지만, 성능 면에서는 이론상 O(L)의 효율적인 탐색구조를 가졌으므로 BinarySearchRouter보다 성능은 더 좋아야 했으나 그렇지 않은 결과를 보여줬기 때문이다.
Java 컬렉션 API에 Trie가 없어, 직접 구현한 Trie 방식에 문제가 있을 것이라고 판단했다. match 메소드의 책임은 사용자에게 요청이 온 uri을 받아 가장 적합한 접두사 매칭된 서블릿을 반환하는 메소드이다.
URL파싱 부분의 String.split()이 매번 새로운 String 객체들과 String[] 배열을 힙메모리에 생성하기 때문에 URL가 길고 세그먼트가 많을수록 이 오버헤드가 커지는 않을까 가정을 하여 개선해보기로 하였다.
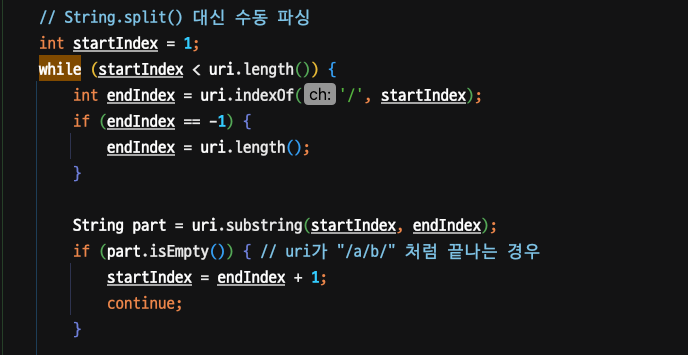
2차 벤치마크 - 처리량(Throughput)
개선 후 TrieRouter 처리량이 BinarySearchRouter 보다 20~40%정도 우수한 성능을 보인다.
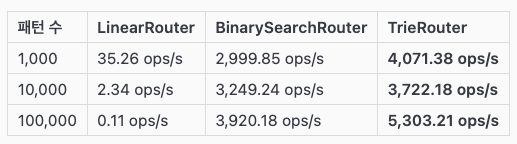
TrieRouter > BinarySearchRouter > LinearRouter
2차 벤치마크 - 힙 메모리 사용량(B/op)
개선 후에는 TrieRouter는 예상보다 메모리 효율도 BinarySearchRouter 보다 약 40% 낮은 할당량을 보였다.
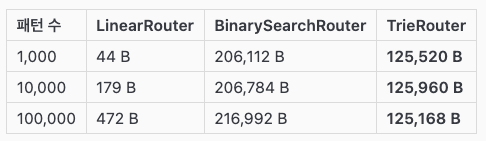
LinearRouter < TrieRouter < BinarySearchRouter
Trie 도입 여부에 대한 판단
Trie는 접두사 매칭(Prefix Match)에 특화된 자료구조로, 패턴 수가 많고 충돌이 잦은 환경에서 탁월한 성능을 보여준다. 그러나 현 시스템에선 다음 이유로 도입을 보류하기로 했다.
첫째, 대부분의 요청이 /static/css/main.css, /api/user/123처럼 정확한 매칭으로 처리된다. 접두사 매칭이 차지하는 비중이 극히 낮아, 현재 HashMap 기반 O(1) 조회 체계에서 성능 병목이 발생하지 않는다. 접두사 매칭이 차지하는 비율이 극히 낮은 상태에서 Trie를 도입해도 체감 성능 개선효과는 미미할 것을 판단된다.
둘째, Java 표준 컬렉션에 Trie 구현이 없으므로 직접 설계 유지해야한다. 위에 측정한 결과처럼 자칫 조금의 최적화 포인트를 놓치면 Binary Search 보다 성능과 메모리 오버헤드가 좋지 않은 상황이 벌어질 것이다.
결론적으로, 접두사 매칭의 성능 최적화를 Trie로 구현하는 방안은 기술적으로 유효하지만, 실제 사용 빈도, 시스템의 복잡도 증가, 메모리 오버헤드 등을 종합적으로 고려했을 때, 현재는 도입하지 않는 것이 더 바람직하다고 판단했다.
향후 해당 기능의 사용빈도가 증가하거나, 성능 병목이 실제로 관측될 경우, 실제 환경에서 메모리 사용량 평가를 바탕으로 도입을 재검토할 여지는 열어두고 있다.
'Java' 카테고리의 다른 글
| 다양한 I/O 모델을 지원하기 위한 Connector 구조 개선 (0) | 2025.05.31 |
|---|---|
| 오픈소스 분석 - Tomcat 소켓 I/O 동작 방식 파헤쳐보기(BIO, NIO Connector) (0) | 2025.05.28 |
| 자바에서는 멀티플렉싱을 어떻게 지원할까? – Java NIO의 Selector (0) | 2025.05.15 |
| Servlet과 Servlet Container 동작 과정의 이해 (3) | 2025.04.09 |
| 자바에서 스레드 풀 사용하기 (0) | 2025.02.18 |