
티스토리 뷰
개요
멀티 스레드는 하나의 프로세스 내에 여러 개의 코드 실행흐름(스레드)이 동작하는 방식을 말한다. 멀티 프로세스가 프로그램 단위의 멀티 태스킹이라면 멀티 스레드는 프로그램 내부에서의 멀티 태스킹이라 볼 수 있다.
멀티 스레드는 동일한 메모리 공간(코드, 데이터, 힙 영역)을 공유하므로 프로세스보다 더 가볍고, 빠른 데이터 공유가 가능하다. 이러한 이유로 멀티 프로세스보다 멀티 스레드가 자원을 보다 효율적으로 사용할 수 있다.
그러나, 스레드 개수가 지나치게 많아지면 오히려 CPU가 스레드 간의 작업을 전환하는 데 많은 시간을 소비하게 된다. 이를 컨텍스트 스위칭 비용이라고 하며, 스레드 수가 증가할수록 이 비용이 누적되어 성능 저하를 유발할 수 있다. 따라서, 효율적인 병렬 처리를 위해 적절한 개수의 스레드를 유지하는 것이 중요하다.
이러한 문제를 적절히 해결하려면 스레드 풀(Thread Pool)을 사용하는 것이 좋다. 스레드 풀은 일정 개수의 스레드를 미리 생성하여 유지하고, 작업 큐에 들어오는 작업들을 스레드가 하나씩 맡아서 처리하는 방식이다. 이를 통해 불필요한 스레드 생성과 소멸을 줄여 성능을 최적화할 수 있다.
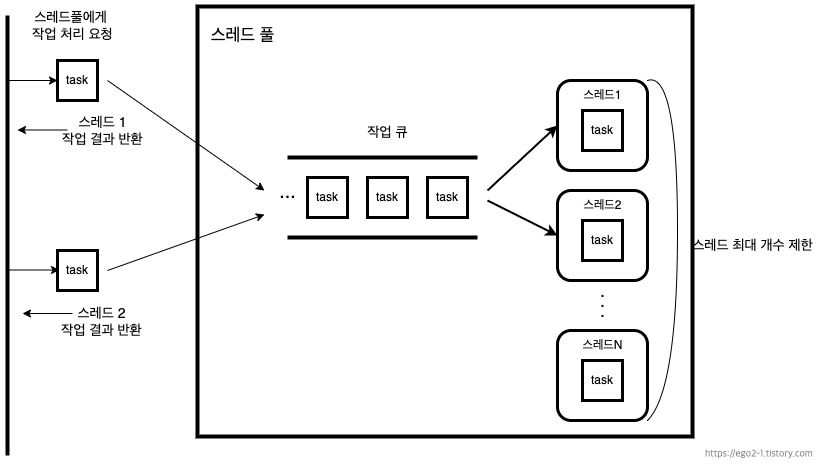
스레드 풀 생성
자바는 스레드 풀을 생성하고 사용할 수 있도록 java.util.concurrent패키지에서 ExecutorService인터페이스와 Excutors 클래스를 제공하고 있다.
Excutors 클래스가 제공하는 정적 메소드를 사용하면 간단하게 스레드 풀인 ExecutorService 구현 객체를 만들 수 있다.
스레드 풀 생성에 등장하는 용어 정리를 간단하게 하고 넘어가겠다.
초기 수: 스레드 풀이 처음 생성될 때 스레드 개수
코어 수: 스레드가 증가된 후 사용하지 않는 스레드를 제거할 때, 최소한에 스레드 풀에 유지하는 스레드 개수
최대 수: 스레드 풀 내에 생성될 수 있는 스레드 최대 개수
newCachedThreadPool()
Excutors 클래스가 제공하는 정적 메소드 newCachedThreadPool()로 생성된 스레드 풀의 초기 수와 코어 수는 0이고, 최대 스레드 수는 Integer.MAX_VALUE이다. 작업 개수가 많아지면 새 스레드를 생성하고 60초 동안 스레드가 아무작업도 하지 않으면 스레드를 풀에서 제거한다.
ExecutorService executorService = Executors.newCachedThreadPool():
newFixedThreadPool()
다음과 같이 newFixedThreadPool(5)로 생성된 스레드풀의 초기 수는 0 개이고, 작업 개수가 많아지면 최대 5개까지 스레드를 생성시켜 작업을 처리한다. 이 스레드풀의 특징은 생성된 스레드를 제거하지 않는다는 것 이다. 즉, 고정된 스레드 수를 갖는다.
ExecutorService executorService = Executors.newFixedThreadPool(5);
ThreadPoolExecutor
ThreadPoolExecutor을 사용해 직접 커스텀한 스레드 풀도 생성할 수 있다.
ExecutorService threadPool = new ThreadPoolExecutor(
3, // 코어 스레드 개수
100, // 최대 스레드 개수
120L, // 놀고 있는 시간
TimeUnit.SECONDS, //놀고있는 시간단위
new SynchronousQueue<Runnable>() // 작업 큐
);
스레드 풀 종료
스레드 풀은 데몬 스레드가 아니므로 Main()스레드가 종료되어도 작업을 처리하기 위해 계속 실행상태로 남아있다. 스레드 풀의 모든 스레드를 종료하려면 ExecutorService에서 제공하는 두 메소드를 사용한다.
shutdown(): 현재 처리 중인 작업뿐만 아니라 작업 큐에 대기하고 있는 모든 작업을 처리한 뒤 스레드풀을 종료한다.
shutdownNow(): 스레드를 interrupt해서 작업을 중지하고, 스레드 풀을 종료한다. 작업 큐에 남아있는 미처리된 작업(Runnable)들의 목록이 반환된다.
threadPool.shutdown();
List<Runnable> unprocessedTasks = threadPool.shutdownNow();
스레드 작업 단위와 처리 요청 보내기
하나의 작업은 Runnable또는 Callable인터페이스로 표현된다. Runnable와 Callable의 차이점은 작업 처리 후 리턴값이 있냐 없냐의 차이이다. Callable은 제네릭을 사용해 스레드의 실행 결과를 받을 수 있다.
[Runnable익명 구현 객체]
new Runnable() {
@Override
public void run() {
// 스레드가 처리할 내용
}
}
new Callable<T>() {
@Override
public T call() throws Exception {
// 스레드가 처리할 내용
return T;
}
}위에 해당 작업을 스레드 풀에 처리 요청을 하려면 작업 큐에 해당 Runnable과 Callable인터페이스 구현 객체를 넣어 줘야한다. ExecutorService의 execute(), submit()메소드로 가능하다.
Runnable 작업 요청 하기
execute()메소드를 사용해 Runnable 구현체를 작업 큐에 추가할 수 있다. 작업을 처리할 스레드가 스레드 풀에 있다면 작업 큐에 Runnable를 꺼내에 run() 메소드를 실행하여 작업을 처리한다.
[Runnable 작업 처리 과정]
public class TreadTest {
public static void main(String[] args) {
String[][] mails = new String[1000][3];
for (int i = 0; i < mails.length; i++) {
mails[i][0] = "admin@my.com";
mails[i][1] = "memeber"+i+"@my.com";
mails[i][2] = "신상품입고";
}
// ExecutorService 생성, 스레드 5개 고정
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 이메일 보내는 작업 생성
for (int i = 0; i < 1000; i++) {
final int idx = i;
executorService.execute(new Runnable() {
@Override
public void run() {
Thread thread = Thread.currentThread();
String from = mails[idx][0];
String to = mails[idx][1];
String content = mails[idx][2];
System.out.println("["+thread.getName()+"] "+from+ "==> " + to+ ": " + content);
}
});
}
// ExecutorService 종료
executorService.shutdown();
}
}
Callable 작업 요청하기
submit()메서드를 사용하면 Callable 인터페이스 구현객체를 작업 큐에 추가할 수 있다. 이 메서드는 비동기적 실행 결과를 추적할 수 있도록 Future 객체를 반환한다.
[Callable 작업 처리 과정]
public class TreadTest {
public static void main(String[] args) {
// ExecutorService 생성, 스레드 5개 고정
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 계산 작업 생성 및 처리 요청
for (int i = 0; i < 1000; i++) {
final int idx = i;
Future<Integer> future = executorService.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= idx; i++) {
sum += i;
}
Thread thread = Thread.currentThread();
System.out.println("["+thread.getName()+"] 1~" + idx + " 합 계산");
return sum;
}
});
try {
int result = future.get(); // 주의: 메인 스레드 브로킹됨!
System.out.println("\t리턴값: " + result);
} catch (Exception e) {
e.printStackTrace();
}
}
// ExecutorService 종료
executorService.shutdown();
}
}
블로킹 방식 future.get()의 함정
위 코드의 작업 과정을 정리하면, 먼저 Executors.newFixedThreadPool(5)을 사용하여 최대 5개의 스레드를 가진 스레드 풀을 생성한다. 초기에는 스레드가 0개이지만, 작업 요청이 들어오면 최대 5개까지 증가하며 그 이상은 스레드가 증가하지 않는다.
submit() 메서드를 사용하면 Callable 객체를 작업 큐에 추가할 수 있으며, 즉시 Future 객체를 반환한다. 이후, Callable의 call() 메서드는 하나의 작업 스레드가 점유하여 실행되며, 작업이 완료된 후 결과를 반환한다.
이 과정은 메인 스레드와 독립적으로 동작하고, Future를 즉시 반환하기 때문에 비동기 + 논블로킹 방식이라고 볼 수 있다.
하지만 문제는 다음부터이다. future.get()을 호출하면 해당 작업이 완료되어 결과 값이 반환될때까지 메인 스레드는 블로킹이되고, 결과를 기다리는 동안 다른 작업을 수행하지 못한다. 즉, submit()을 통해 Callable을 실행하면 작업 자체는 비동기적으로 실행되지만, 결과를 얻는 과정에서 블로킹이 발생할 수 있다.
future.get()에 타임아웃 시간을 설정해 일정 시간이 지나면 작업을 취소하도록 하여 영원히 응답을 기다리는 상황을 방지할 수 있지만 이 방법도 블로킹이 되는 것을 개선할 수는 없다.
Future의 한계를 보완하기 위해 Java 8에서는 CompletableFuture가 추가되었다. 이를 활용하면 콜백 함수를 미리 지정하여 블로킹 없이 작업이 완료된 후 자동으로 지정한 콜백 함수를 실행하도록 설정할 수 있다. 이를 통해 보다 완전한 비동기 처리가 가능해진다.
참고 자료
- 신용권, 이것이 자바다(개정판), 2022.09.05 한빛 미디어
- Method call to Future.get() blocks. Is that really desirable?, stackoverflow
'Java' 카테고리의 다른 글
| 다양한 I/O 모델을 지원하기 위한 Connector 구조 개선 (0) | 2025.05.31 |
|---|---|
| 오픈소스 분석 - Tomcat 소켓 I/O 동작 방식 파헤쳐보기(BIO, NIO Connector) (0) | 2025.05.28 |
| 자바에서는 멀티플렉싱을 어떻게 지원할까? – Java NIO의 Selector (0) | 2025.05.15 |
| 접두사 기반 URL 탐색 구조 성능 측정 및 최적화 (0) | 2025.05.05 |
| Servlet과 Servlet Container 동작 과정의 이해 (3) | 2025.04.09 |